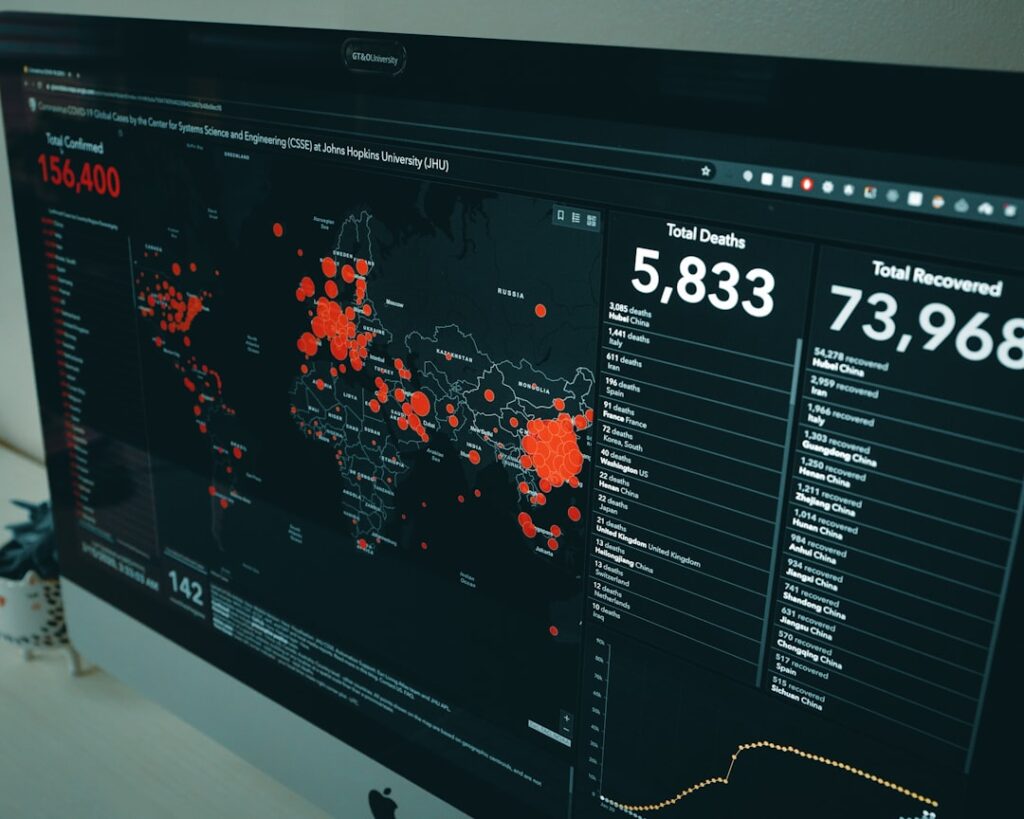
Statistical learning is a framework that encompasses a variety of techniques for understanding and modeling complex data. At its core, it combines statistical theory with machine learning principles to extract meaningful insights from data. This discipline is particularly valuable in an era where vast amounts of data are generated daily, necessitating robust methods for analysis and interpretation.
Supervised learning involves training a model on a labeled dataset, where the outcome variable is known. This approach allows for predictions about future or unseen data based on the patterns learned from the training set.
In contrast, unsupervised learning deals with unlabeled data, focusing on discovering inherent structures or groupings within the dataset. Techniques such as clustering and dimensionality reduction fall under this category, enabling analysts to uncover hidden relationships without predefined labels. Understanding these foundational concepts is crucial for anyone looking to delve into the world of data science and analytics.
Key Takeaways
- Statistical learning involves understanding and making predictions based on data using statistical techniques.
- R programming is a powerful tool for statistical analysis and data visualization.
- Data analysis techniques help in understanding and interpreting patterns and trends in data.
- Predictive modeling and machine learning are used to make predictions and decisions based on data.
- Classification and regression methods are used to categorize and predict numerical outcomes based on input variables.
Introduction to R Programming
R programming has emerged as one of the leading languages for statistical computing and data analysis. Its popularity stems from its extensive libraries and packages specifically designed for statistical modeling, making it an invaluable tool for statisticians and data scientists alike. R provides a flexible environment that supports a wide range of statistical techniques, from basic descriptive statistics to complex machine learning algorithms.
The language’s syntax is particularly well-suited for data manipulation and visualization, allowing users to perform intricate analyses with relative ease. One of the key advantages of R is its active community, which contributes to a rich ecosystem of packages that extend its capabilities. For instance, packages like ggplot2 facilitate advanced data visualization, while dplyr simplifies data manipulation tasks.
Additionally, R’s integration with other programming languages and tools enhances its versatility, enabling users to leverage its strengths alongside other technologies. As organizations increasingly rely on data-driven decision-making, proficiency in R programming has become a highly sought-after skill in the job market.
Exploring Data Analysis Techniques
Data analysis techniques are essential for transforming raw data into actionable insights. These techniques can be broadly classified into descriptive, inferential, and predictive analytics. Descriptive analytics focuses on summarizing historical data to identify trends and patterns.
This can involve calculating measures such as mean, median, mode, and standard deviation, as well as creating visualizations like histograms and box plots to illustrate distributions. Inferential analytics takes this a step further by using sample data to make inferences about a larger population. Techniques such as hypothesis testing and confidence intervals are commonly employed in this realm.
For example, a researcher might use inferential statistics to determine whether a new drug is effective based on a sample of patients. Predictive analytics, on the other hand, leverages historical data to forecast future outcomes. This often involves the use of machine learning algorithms that can identify complex relationships within the data, allowing for more accurate predictions.
Predictive Modeling and Machine Learning
Predictive modeling is a cornerstone of statistical learning that focuses on creating models capable of forecasting future events based on historical data. This process typically involves selecting appropriate algorithms, training models on historical datasets, and validating their performance against unseen data. Machine learning plays a pivotal role in predictive modeling by providing sophisticated algorithms that can learn from data without being explicitly programmed.
Common machine learning techniques used in predictive modeling include decision trees, support vector machines, and neural networks. Each of these methods has its strengths and weaknesses, making it essential for practitioners to understand the context of their application. For instance, decision trees are intuitive and easy to interpret but may suffer from overfitting if not properly managed.
In contrast, neural networks can capture complex patterns but require substantial computational resources and careful tuning of hyperparameters.
Classification and Regression Methods
Classification and regression are two fundamental types of supervised learning methods used in statistical learning. Classification involves predicting categorical outcomes based on input features. For example, an email filtering system might classify messages as “spam” or “not spam” based on various attributes such as sender information and content keywords.
Common algorithms used for classification include logistic regression, k-nearest neighbors (KNN), and random forests. Regression methods, on the other hand, are employed when the outcome variable is continuous. For instance, predicting house prices based on features like square footage, location, and number of bedrooms would fall under regression analysis.
Linear regression is one of the simplest forms of regression analysis, establishing a linear relationship between independent variables and the dependent variable. More complex methods such as polynomial regression or ridge regression can be utilized when relationships are non-linear or when multicollinearity is present among predictors.
Model Evaluation and Validation
Model evaluation and validation are critical steps in the machine learning workflow that ensure the reliability and generalizability of predictive models. Various metrics are employed to assess model performance, including accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC). These metrics provide insights into how well a model performs on both training and validation datasets.
Cross-validation is a widely used technique for model validation that helps mitigate overfitting by partitioning the dataset into multiple subsets. In k-fold cross-validation, for example, the dataset is divided into k subsets; the model is trained on k-1 subsets while being validated on the remaining subset. This process is repeated k times, allowing each subset to serve as a validation set once.
Unsupervised Learning and Clustering
Unsupervised learning is a category of statistical learning that deals with datasets lacking labeled outcomes. The primary goal is to uncover hidden structures or patterns within the data without prior knowledge of what those patterns might be. Clustering is one of the most common techniques used in unsupervised learning, where similar data points are grouped together based on their characteristics.
Several clustering algorithms exist, each with its unique approach to grouping data points. K-means clustering is one of the most popular methods due to its simplicity and efficiency; it partitions data into k clusters by minimizing the variance within each cluster. Hierarchical clustering offers another approach by creating a tree-like structure that represents nested clusters at various levels of granularity.
Applications of clustering range from market segmentation in business to image recognition in computer vision.
Real-world Applications of Statistical Learning
The applications of statistical learning are vast and varied across numerous fields, reflecting its versatility in addressing real-world challenges. In healthcare, predictive modeling can be employed to forecast patient outcomes based on historical medical records, enabling healthcare providers to tailor treatments more effectively. For instance, machine learning algorithms can analyze patient demographics and clinical histories to predict the likelihood of readmission after surgery.
In finance, statistical learning techniques are utilized for credit scoring and fraud detection. By analyzing transaction patterns and customer behavior, financial institutions can identify potentially fraudulent activities in real-time. Similarly, in marketing, businesses leverage customer segmentation through clustering techniques to target specific demographics with tailored advertising campaigns.
Moreover, industries such as agriculture use statistical learning for precision farming by analyzing environmental data to optimize crop yields. In technology sectors like e-commerce, recommendation systems powered by collaborative filtering algorithms enhance user experience by suggesting products based on past purchases or browsing behavior. The breadth of applications underscores the importance of statistical learning as a critical tool for decision-making across various domains.
As technology continues to evolve and data becomes increasingly abundant, the relevance of statistical learning will only grow stronger in shaping our understanding of complex systems and driving innovation across industries.
If you are interested in learning more about statistical learning and its applications, you may want to check out the article “Hello World” on Hellread.com. This article provides a beginner-friendly introduction to programming and data analysis, which can be a great complement to the concepts discussed in “An Introduction to Statistical Learning with Applications in R” by Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. You can read the article here.
FAQs
What is “An Introduction to Statistical Learning with Applications in R” about?
The book “An Introduction to Statistical Learning with Applications in R” provides an introduction to statistical learning methods and their applications in R. It covers topics such as linear regression, classification, resampling methods, tree-based methods, support vector machines, and unsupervised learning.
Who are the authors of “An Introduction to Statistical Learning with Applications in R”?
The authors of “An Introduction to Statistical Learning with Applications in R” are Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. They are all experts in the field of statistical learning and have extensive experience in teaching and research.
What is R and how is it used in the book?
R is a programming language and software environment for statistical computing and graphics. In the book, R is used to demonstrate the application of statistical learning methods through practical examples and exercises. Readers are encouraged to use R to implement the techniques discussed in the book.
Who is the target audience for “An Introduction to Statistical Learning with Applications in R”?
The book is intended for students and professionals who are interested in learning about statistical learning methods and their practical applications. It is suitable for individuals with a background in statistics, mathematics, or a related field, and who have some familiarity with programming.
What are some of the topics covered in “An Introduction to Statistical Learning with Applications in R”?
The book covers a wide range of topics, including linear regression, classification, resampling methods, tree-based methods, support vector machines, unsupervised learning, and more. It also includes practical examples and case studies to illustrate the application of these methods.





